一、简介
Java代码的混淆不只有ProGuard,还有像yGuard、Facebook ProGuard分支等,但ProGuard在被使用上占有绝对优势,常见问题更容易找到解决办法。
ProGuard是一个混淆代码的开源项目,它的主要作用是混淆代码,ProGuard包括以下4个功能。
压缩(Shrink):检测并移除代码中无用的类、字段、方法和特性(Attribute)。
优化(Optimize):对字节码进行优化,移除无用的指令。
混淆(Obfuscate):使用a,b,c,d这样简短而无意义的名称,对类、字段和方法进行重命名。
预检(Preveirfy):在Java平台上对处理后的代码进行预检,确保加载的class文件是可执行的。
根据官网的翻译:Proguard是一个Java类文件压缩器、优化器、混淆器、预校验器。压缩环节会检测以及移除没有用到的类、字段、方法以及属性。优化环节会分析以及优化方法的字节码。混淆环节会用无意义的短变量去重命名类、变量、方法。这些步骤让代码更精简,更高效,也更难被逆向(破解)。
这里只讲部分ProGuard混淆的在开发工具(以Eclipse为例)中简单使用。
ProGuard是Java开发的也有GUI版本等其他形式,有兴趣的自行研究使用。
二、参数
1. 基本指令
# 代码混淆压缩比,在0和7之间,默认为5,一般不需要改
-optimizationpasses 5
# 混淆时不使用大小写混合,混淆后的类名为小写
-dontusemixedcaseclassnames
# 指定不去忽略非公共的库的类
-dontskipnonpubliclibraryclasses
# 指定不去忽略非公共的库的类的成员
-dontskipnonpubliclibraryclassmembers
# 不做预校验,preverify是proguard的4个步骤之一
# Android不需要preverify,去掉这一步可加快混淆速度
-dontpreverify
# 有了verbose这句话,混淆后就会生成映射文件
# 包含有类名->混淆后类名的映射关系
# 然后使用printmapping指定映射文件的名称
-verbose
-printmapping proguardMapping.txt
# 指定混淆时采用的算法,后面的参数是一个过滤器
# 这个过滤器是谷歌推荐的算法,一般不改变
-optimizations !code/simplification/arithmetic,!field/*,!class/merging/*
# 保护代码中的Annotation不被混淆,这在JSON实体映射时非常重要,比如fastJson
-keepattributes *Annotation*
# 避免混淆泛型,这在JSON实体映射时非常重要,比如fastJson
-keepattributes Signature
//抛出异常时保留代码行号,在异常分析中可以方便定位
-keepattributes SourceFile,LineNumberTable
-dontskipnonpubliclibraryclasses用于告诉ProGuard,不要跳过对非公开类的处理。默认情况下是跳过的,因为程序中不会引用它们,有些情况下人们编写的代码与类库中的类在同一个包下,并且对包中内容加以引用,此时需要加入此条声明。
-dontusemixedcaseclassnames,这个是给Microsoft Windows用户的,因为ProGuard假定使用的操作系统是能区分两个只是大小写不同的文件名,但是Microsoft Windows不是这样的操作系统,所以必须为ProGuard指定-dontusemixedcaseclassnames选项
例:(此示例为pom.xml文件配置形式,下同)
参考:https://www.guardsquare.com/en/products/proguard/manual/usage
2.不混淆的内容
注意:所有预加载、项目启动初始化的类,被jar包引用的类(本身也不建议这么写),继承自项目所使用框架或其他依赖的类的子类,枚举类,自定义控件、过滤器,Serializable序列化的类等,以上这些不建议进行混淆。
后期谁如有遇到其他不能进行混淆的,请自行补遗!
#需要保持的属性:异常,注解等
-keepattributes Exceptions,InnerClasses,Signature,Deprecated,SourceFile,LocalVariable*Table,*Annotation*,Synthetic,EnclosingMethod
#不混淆所有的set/get方法
-keepclassmembers public class * {void set*(***);*** get*();}
# 保留public、protected方法不被混淆
-keep public class * { public protected *; }
# 保留注解不被混淆
-keep public @interface * { ** default (*);}
# 保留枚举类不被混淆
-keepclassmembers enum * { public static **[] values(); public static ** valueOf(java.lang.String);}
# 保持依赖注入不被混淆
-keepclassmembers class * { @org.springframework.beans.factory.annotation.Autowired *; @javax.annotation.Resource *;}
# 避免类名被标记为final
-optimizations !class/marking/final
# 保留JavaBean不被混淆
-keepclassmembers class * implements java.io.Serializable {
static final long serialVersionUID;
private static final java.io.ObjectStreamField[] serialPersistentFields;
private void writeObject(java.io.ObjectOutputStream);
private void readObject(java.io.ObjectInputStream);
java.lang.Object writeReplace();
java.lang.Object readResolve(); }
JavaBean不被混淆也可直接写包路径,如下:
-keep class com.xxx.xxx.bean.** { *;}
#不混淆包下的所有类名,且类中的方法也不混淆的写法
-keep class com.xxx.xxx.xxx { <methods>; }
或
-keep class com.xxx.xxx.xxx.** { <methods>; }
-keep class com.xxx.xxx.xxx.** { *; }
例:

三、配置
这里使用pom.xml的配置形式,在pom.xml中加入
<!-- ProGuard混淆插件-->
<plugin>
<groupId>com.github.wvengen</groupId>
<artifactId>proguard-maven-plugin</artifactId>
<version>2.0.14</version>
<executions>
<execution>
<!-- 混淆时刻,这里是打包的时候混淆-->
<phase>package</phase>
<goals>
<!-- 使用插件的什么功能,混淆-->
<goal>proguard</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- 是否将生成的PG文件安装部署-->
<attach>true</attach>
<!-- 是否混淆-->
<obfuscate>true</obfuscate>
<!-- 指定生成文件分类 -->
<attachArtifactClassifier>pg</attachArtifactClassifier>
<options>
<!-- JDK目标版本1.8-->
<option>-target 1.8</option>
<!-- 不做收缩(删除注释、未被引用代码)-->
<option>-dontshrink</option>
<!-- 不做优化(变更代码实现逻辑)-->
<option>-dontoptimize</option>
<!-- 不路过非公用类文件及成员-->
<option>-dontskipnonpubliclibraryclasses</option>
<option>-dontskipnonpubliclibraryclassmembers</option>
<!--不用大小写混合类名机制-->
<option>-dontusemixedcaseclassnames</option>
<!-- 优化时允许访问并修改有修饰符的类和类的成员 -->
<option>-allowaccessmodification</option>
<!-- 确定统一的混淆类的成员名称来增加混淆-->
<option>-useuniqueclassmembernames</option>
<!-- 不混淆所有包名-->
<!--<option>-keeppackagenames</option>-->
<!-- 需要保持的属性:异常,注解等-->
<option>-keepattributes Exceptions,InnerClasses,Signature,Deprecated,SourceFile,LocalVariable*Table,*Annotation*,Synthetic,EnclosingMethod</option>
<!-- 不混淆所有的set/get方法->
<option>-keepclassmembers public class * {void set*(***);*** get*();}</option>
<!-- 不混淆包下的所有类名,且类中的方法也不混淆-->
<option>-keep class com.xxx.xxx.bboss.SystemConfig { <methods>; }</option>
<option>-keep class com.xxx.xxx.xxx.controller.** { <methods>; }</option>
<option>-keep class com.xxx.xxx.xxx.exception { <methods>; }</option>
<option>-keep class com.xxx.xxx.xxx.model.** { *; }</option>
</options>
<!--class 混淆后输出的jar包-->
<outjar>classes-autotest.jar</outjar>
<!-- 添加依赖,这里你可以按你的需要修改,这里测试只需要一个JRE的Runtime包就行了 -->
<libs>
<lib>${java.home}/lib/rt.jar</lib>
</libs>
<!-- 对什么东西进行加载,这里仅有classes成功-->
<injar>classes</injar>
<!-- 输出目录-->
<outputDirectory>${project.build.directory}</outputDirectory>
</configuration>
</plugin>
以上参数和相关配置根据自身项目及需求进行相应修改
后续就是正常的打包流程,更新项目,运行 mvn clean package -DskipTests
如下:
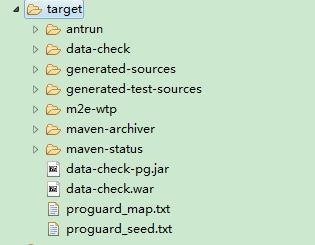
data-check-pg.jar中是混淆之后的class,未包含任何配置等内容,只有\classes路径内容;
data-check.war即为混淆后的web项目(若没有混淆,则把data-check-pg.jar解压拷入);
proguard_map.txt混淆内容映射;
proguard_seed.txt参与混淆的类
混淆效果:可以看到源文件行号已经无法还原,普通成员变量、本地变量的变量名已经替换成无意义名字,代码结构有很细微的变化不影响结果。经过混淆和优化后,比原始的class文件小了大致20%左右。
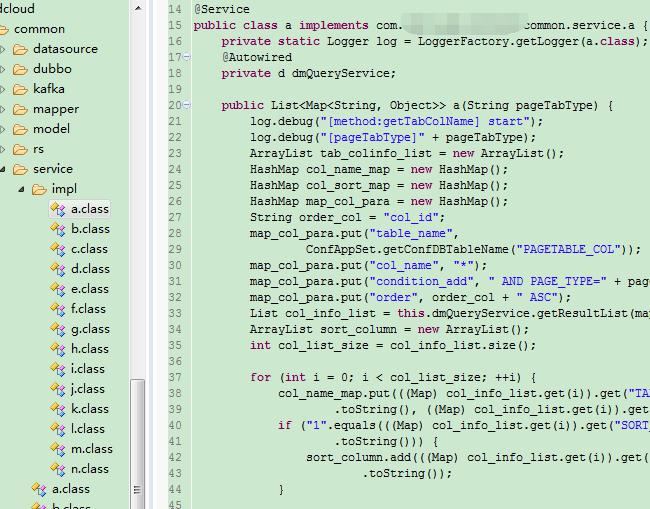
混淆后部分包名跟类名已经被改为了简单字母,不再具有业务含义,而且变量名也进行了修改,增加了阅读代码难度。
运行服务,项目正常运行即混淆成功。
注意事项:
1、因为有时候会配置不保持包名或类名,因此一些相关配置文件的内容需要改变,好在ProGuard不是随机生成类名,而是先按照原名称对相同包下类进行排序,混淆后的类名称依次为a.class,b.class,c.class.....
那么问题来了,当包中超过26个类时,默认命名为A.class,B.class,C.class,在某些操作系统下,会不区分class文件名称的大小写,会导致错误(水平所限,未深入探究跟类加载相关);因此
<!--不用大小写混合类名机制-->
<option>-dontusemixedcaseclassnames</option>
配置极为关键,该配置会在超过26个类文件时,命名为aa.class,ab.class,ac.class,而不是原来的大写类名,从而避免错误。
2、书写代码时需要考虑混淆后是否影响运行
比如JavaBean混淆后,类成员变量的名称可以变掉,方法名不变。这时候如果成员变量有注解类似于@JsonIgnore、@JSONField(serialize=XX)可能会失效,正确的应该把这些注解写到Setter方法上。
或者直接对JavaBean不进行混淆。
3、需要考虑Debug的便利性
混淆可以优化代码,去除字节码中关联的行号信息,这时候发布出去的项目如果出错,日志会相对难调试。这个是双刃剑,要么接受混淆,要么通过控制参数保留行号信息。



发表吐槽
你肿么看?
既然没有吐槽,那就赶紧抢沙发吧!