数据库需要适应各种语言和字符就需要支持不同的字符集(Character Set),每种字符集也有各自的排序规则(Collation)。
(注意:Collation原意为校对,校勘,但是根据实际使用场景,觉得还是翻译为排序规则比较合适)
在绝大部分情形中,使用何种字符集和排序规则决定于服务器,数据库和表的级别,一般SQL操作不必关心这些。
以下操作均以MySQL为例。
查看数据库支持的字符集与排序规则
查看字符集:
SHOW CHARACTER SET;
部分结果:


查看排序规则:
SHOW COLLATION;
部分结果:


排序方式的命名规则为:字符集名字_语言_后缀,其中各个典型后缀的含义如下:
1)_ci:不区分大小写的排序方式( Case Insensitve))
2)_cs:区分大小写的排序方式(Case Sensitive)
3)_bin:二进制排序方式,大小比较将根据字符编码,不涉及人类语言,因此_bin的排序方式不包含人类语言
使用数据库支持的字符集与排序规则
通常系统管理在安装时定义一个默认的字符集和排序规则,
也可以在创建数据库时对数据库范围,建表时对表级别,甚至列级别设置字符集和排序规则。
> 下图为建数据库时指定字符集和排序规则:
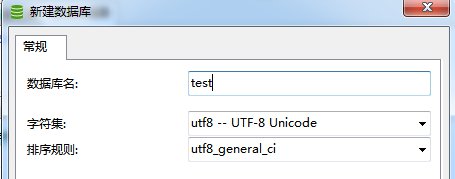

为了确定所用的字符集和排序规则,可以使用下列语句:
SHOW VARIABLES LIKE 'character%'; SHOW VARIABLES LIKE 'collation%';
> 建表时指定表的字符集和排序规则:
1 CREATE TABLE mytable ( 2 column1 INT, 3 column2 VARCHAR (10) 4 ) DEFAULT CHARACTER SET hebrew 5 COLLATE hebrew_general_ci;
不指定字符集和排序规则时使用数据库默认设置,若指定了字符集没有指定排序规则,则使用字符集的默认排序规则。
>建表时指定表和列的字符集和排序规则

CREATE TABLE mytable ( column1 INT, column2 VARCHAR (10), column3 VARCHAR (10) CHARACTER SET latin1 COLLATE latin1_general_ci ) DEFAULT CHARACTER SET hebrew COLLATE hebrew_general_ci;
>自定义查询语句中ORDER BY的排序规则
SELECT * FROM `mytable` ORDER BY `column1` COLLATE latin1_general_cs;
这里的使用不限于ORDER BY,还有GROUP BY,聚集函数等。



发表吐槽
你肿么看?
既然没有吐槽,那就赶紧抢沙发吧!